Big Data Technologies
Big Data Analytics - Assignment-2
1.MAP REDUCE
Introduction
MapReduce is part of the Apache Hadoop ecosystem, a framework that develops large-scale data processing. Other components of Apache Hadoop include Hadoop Distributed File System (HDFS), Yarn, and Apache Pig. This component develops large-scale data processing using scattered and compatible algorithms in the Hadoop ecosystem. This editing model is used in social media and e-commerce to analyze extensive data collected from online users. This article provides insight into MapReduce on Hadoop. It will allow readers to discover details about how much data is simplified and how it is applied to real-life programs.

MapReduce is a Hadoop framework used to write applications that can process large amounts of data in large volumes. It can also be called an editing model where we can process large databases in all computer collections. This application allows data to be stored in distributed form, simplifying a large amount of data and a large computer. There are two main functions in MapReduce: map and trim. We did the previous work before saving. In the map function, we split the input data into pieces, and the map function processes these pieces accordingly.
A map that uses output as input for reduction functions. The scanners process medium data from maps to smaller tuples, which reduces tasks, leading to the final output of the frame. This framework improves planning and monitoring activities, and failed jobs are restructured by frame. Programmers can easily use this framework with little experience in distributed processing. MapReduce can use various programming languages such as Java, Live, Pig, Scala, and Python.
MapReduce architecture
The following diagram shows the MapReduce structure.
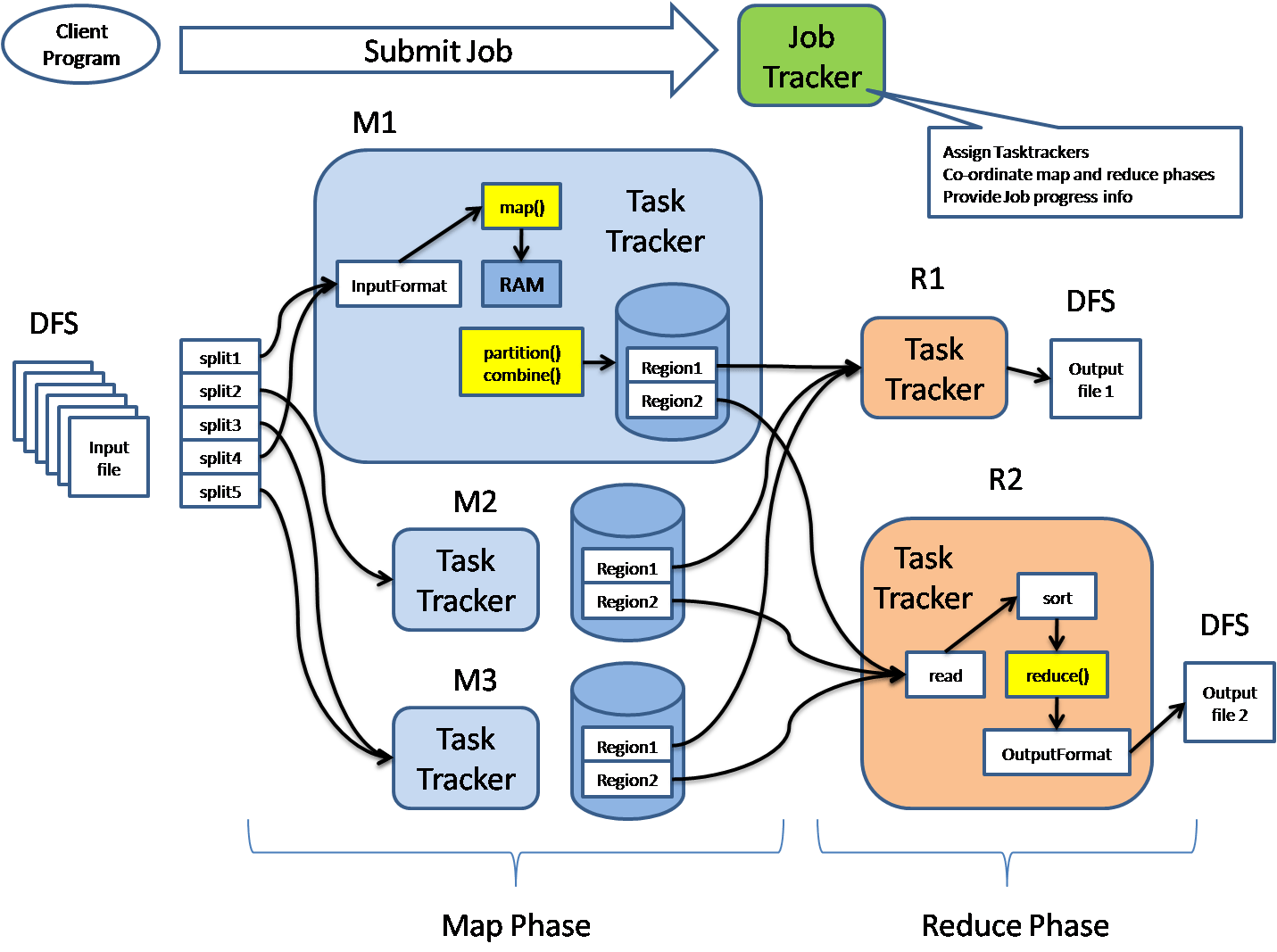
MapReduce architecture consists of various components
A brief description of these sections can enhance our understanding of how it works.
- Job: This is real work that needs to be done or processed
- Task: This is a piece of real work that needs to be done or processed. The MapReduce task covers many small tasks that need to be done.
- Job Tracker: This tracker plays a role in organizing tasks and tracking all tasks assigned to a task tracker.
- Task Tracker: This tracker plays the role of tracking activity and reporting activity status to the task tracker.
- Input data: This is used for processing in the mapping phase.
- Exit data: This is the result of mapping and mitigation.
- Client: This is a program or Application Programming Interface (API) that sends tasks to MapReduce. It can accept services from multiple clients.
- Hadoop MapReduce Master: This plays the role of dividing tasks into sections.
- Job Parts: These are small tasks that result in the division of the primary function.
In MapReduce architecture, clients submit tasks to MapReduce Master. This manager will then divide the work into smaller equal parts.
The components of the function will be used for two main tasks in Map Reduce: mapping and subtraction.
Phases of MapReduce
The MapReduce program comprises three main stages: mapping, navigation, and mitigation. There is also an optional category known as the merging phase.
- Mapping Phase
This is the first phase of the program. There are two steps in this phase: classification and mapping. The database is divided into equal units called units (input divisions) in the division step. Hadoop contains a RecordReader that uses TextInputFormat to convert input variables into keyword pairs.
- Shuffling phase
This is the second phase that occurs after the completion of the Mapping phase. It consists of two main steps: filtering and merging. In the filter step, keywords are filtered using keys and combining ensures that key-value pairs are included.
The shoplifting phase facilitates the removal of duplicate values and the collection of values. Different values with the same keys are combined. The output of this category will be keys and values, as in the Map section.
- Reducer phase
In the reduction phase, the output of the push phase is user input. The subtractor continuously processes these inputs to reduce the median values into smaller ones. Provides a summary of the entire database. Output in this category is stored in HDFS.
The following diagram illustrates MapReduce with three main categories. Separation is usually included in the mapping phase.
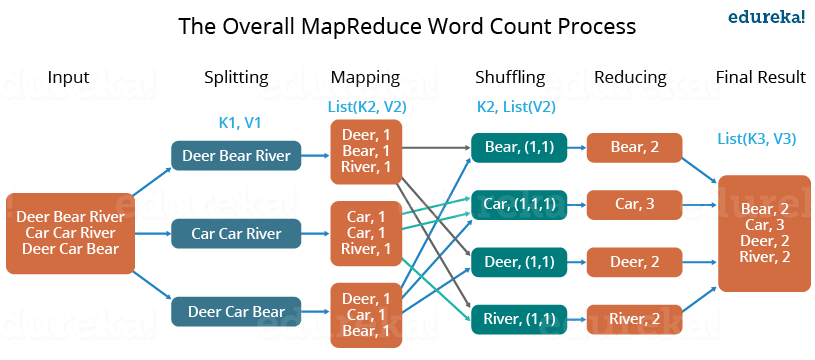
- Combiner phase
This is the optional phase used to improve the MapReduce process. It is used to reduce pap output at the node level. At this stage, duplicate output from the map output can be merged into a single output. The integration phase accelerates the integration phase by improving the performance of tasks.
The following diagram shows how all four categories of MapReduce are used.
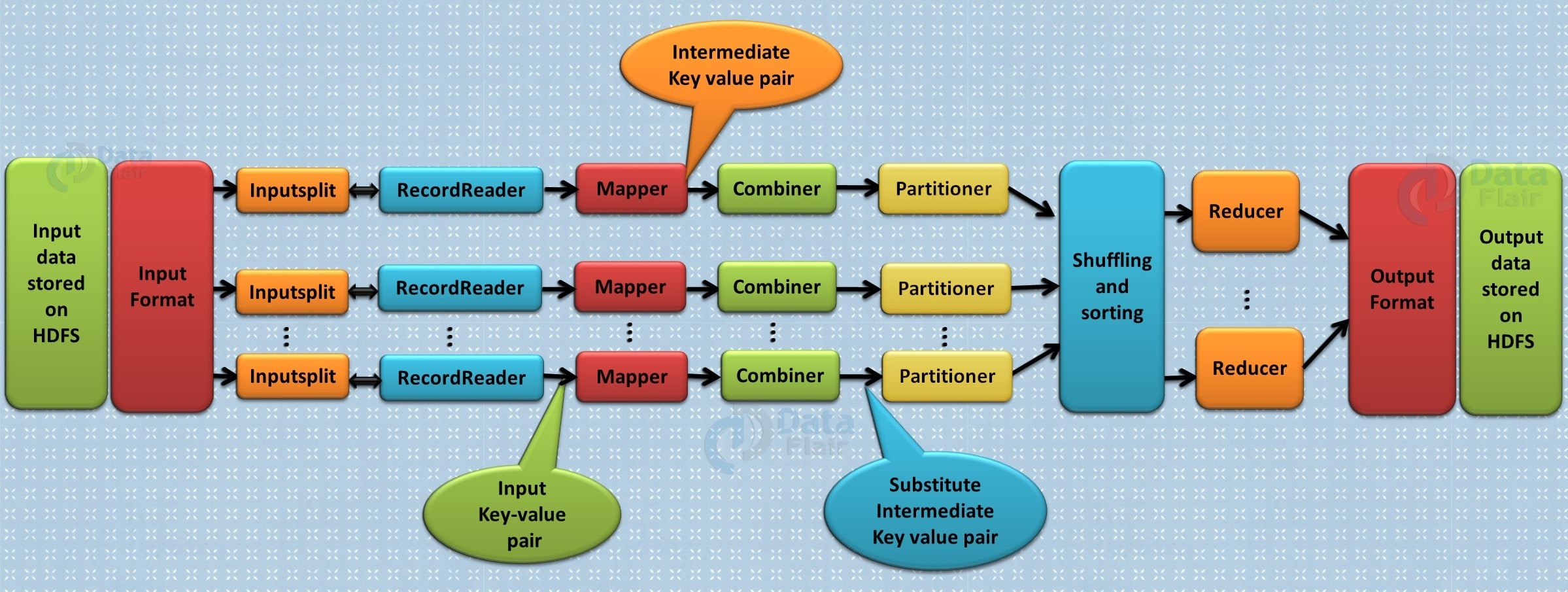
Benefits of Hadoop MapReduce
There are numerous benefits of MapReduce; some of them are listed below.
- Speed: It can process large amounts of random data in a short period.
- Fault tolerance: The MapReduce framework can manage failures.
- Most expensive: Hadoop has a rating feature that allows users to process or store data cost-effectively.
- Scalability: Hadoop provides an excellent framework. MapReduce allows users to run applications on multiple nodes.
- Data availability: Data matches are sent to various locations within the network. This ensures that copies of the data are available in case of failure.
- Parallel Processing: On MapReduce, many parts of the same database functions can be processed similarly. This reduces the time taken to complete the task.
2.APACHE PIG
Introduction

Apache Pig is an abstraction over MapReduce. It is a tool/platform which is used to analyze larger sets of data representing them as data flows. Pig is generally used with Hadoop; we can perform all the data manipulation operations in Hadoop using Apache Pig.
To write data analysis programs, Pig provides a high-level language known as Pig Latin. This language provides various operators using which programmers can develop their own functions for reading, writing, and processing data.
To analyze data using Apache Pig, programmers need to write scripts using Pig Latin language. All these scripts are internally converted to Map and Reduce tasks. Apache Pig has a component known as Pig Engine that accepts the Pig Latin scripts as input and converts those scripts into MapReduce jobs.
Apache Pig Architecture in Hadoop
Apache Pig architecture consists of a Pig Latin interpreter that uses Pig Latin scripts to process and analyze massive datasets. Programmers use Pig Latin language to analyze large datasets in the Hadoop environment. Apache pig has a rich set of datasets for performing different data operations like join, filter, sort, load, group, etc.
Programmers must use Pig Latin language to write a Pig script to perform a specific task. Pig converts these Pig scripts into a series of Map-Reduce jobs to ease programmers’ work. Pig Latin programs are executed via various mechanisms such as UDFs, embedded, and Grunt shells.
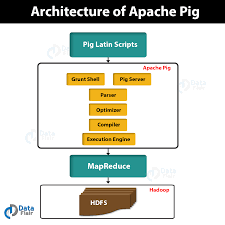
Apache Pig architecture is consisting of the following major components:
- Pig Latin Scripts: Pig scripts are submitted to the Pig execution environment to produce the desired results.
- Parser: Parser handles all the Pig Latin statements or commands. Parser performs several checks on the Pig statements like syntax check, type check, and generates a DAG (Directed Acyclic Graph) output. DAG output represents all the logical operators of the scripts as nodes and data flow as edges.
- Optimizer: Once parsing operation is completed and a DAG output is generated, the output is passed to the optimizer. The optimizer then performs the optimization activities on the output, such as split, merge, projection, pushdown, transform, and reorder, etc. The optimizer processes the extracted data and omits unnecessary data or columns by performing pushdown and projection activity and improves query performance.
- Compiler: The compiler compiles the output that is generated by the optimizer into a series of Map Reduce jobs. The compiler automatically converts Pig jobs into Map Reduce jobs and optimizes performance by rearranging the execution order.
- Execution Engine: After performing all the above operations, these Map Reduce jobs are submitted to the execution engine, which is then executed on the Hadoop platform to produce the desired results. You can then use the DUMP statement to display the results on screen or STORE statements to store the results in HDFS (Hadoop Distributed File System).
- Execution Mode: Apache Pig is executed in two execution modes that are local and Map Reduce. The choice of execution mode depends on where the data is stored and where you want to run the Pig script. You can either store your data locally (in a single machine) or in a distributed Hadoop cluster environment.
- Local Mode : You can use local mode if your dataset is small. In local mode, Pig runs in a single JVM using the local host and file system. In this mode, parallel mapper execution is impossible as all files are installed and run on the localhost. You can use pig -x local command to specify the local mode.
- Map Reduce Mode – Apache Pig uses the Map Reduce mode by default. In Map Reduce mode, a programmer executes the Pig Latin statements on data that is already stored in the HDFS (Hadoop Distributed File System). You can use pig -x mapreduce command to specify the Map-Reduce mode.

Features of Apache Pig
Apache Pig comes with the following features −
Rich set of operators − It provides many operators to perform operations like join, sort, filer, etc.
Ease of programming − Pig Latin is similar to SQL and it is easy to write a Pig script if you are good at SQL.
Optimization opportunities − The tasks in Apache Pig optimize their execution automatically, so the programmers need to focus only on semantics of the language.
Extensibility − Using the existing operators, users can develop their own functions to read, process, and write data.
UDF’s − Pig provides the facility to create User-defined Functions in other programming languages such as Java and invoke or embed them in Pig Scripts.
Handles all kinds of data − Apache Pig analyzes all kinds of data, both structured as well as unstructured. It stores the results in HDFS.
Applications of Apache Pig
Apache Pig is generally used by data scientists for performing tasks involving ad-hoc processing and quick prototyping. Apache Pig is used −
- To process huge data sources such as web logs.
- To perform data processing for search platforms.
- To process time sensitive data loads.
Apache Pig Vs MapReduce
Listed below are the major differences between Apache Pig and MapReduce.
| Apache Pig | MapReduce |
|---|---|
| Apache Pig is a data flow language. | MapReduce is a data processing paradigm. |
| It is a high level language. | MapReduce is low level and rigid. |
| Performing a Join operation in Apache Pig is pretty simple. | It is quite difficult in MapReduce to perform a Join operation between datasets. |
| Any novice programmer with a basic knowledge of SQL can work conveniently with Apache Pig. | Exposure to Java is must to work with MapReduce. |
| Apache Pig uses multi-query approach, thereby reducing the length of the codes to a great extent. | MapReduce will require almost 20 times more the number of lines to perform the same task. |
| There is no need for compilation. On execution, every Apache Pig operator is converted internally into a MapReduce job. | MapReduce jobs have a long compilation process. |
Comments
Post a Comment